
Dennoch ist es kostengünstiger als die Konkurrenz.
DeepSeeks neuer Chatbot stellte sich mit dieser selbstbewussten Aussage vor:
Hey, ich bin darauf ausgelegt, jede Frage mit Einsichten zu beantworten, die dich vielleicht überraschen werden.
DeepSeek hat sich als starker Player in der Branche etabliert und sogar zu einem spürbaren Kursrückgang bei NVIDIA beigetragen.
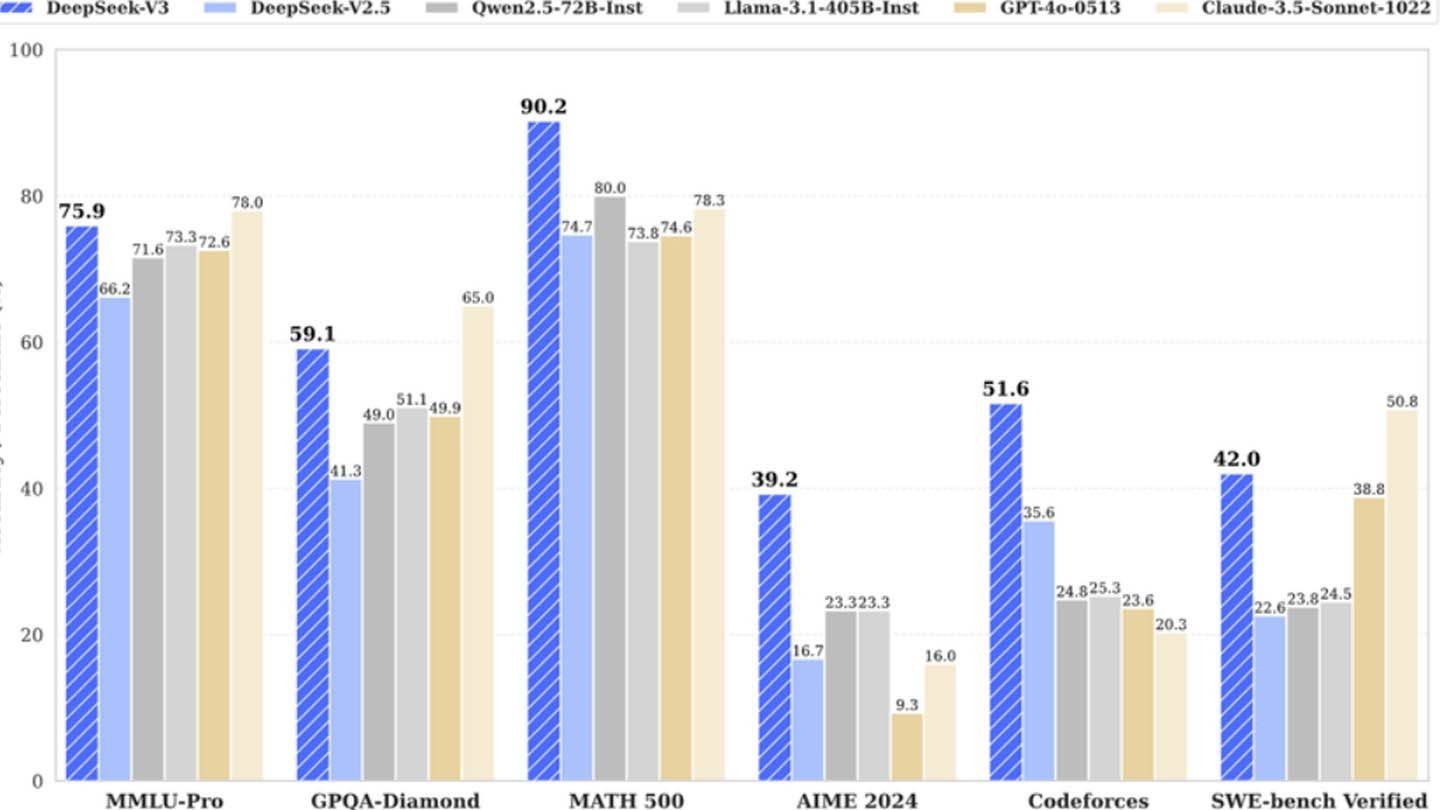 Bild: ensigame.com
Bild: ensigame.com
Die Stärke des Modells liegt in seiner einzigartigen Architektur und Trainingsmethoden, die bahnbrechende Innovationen integrieren:
Multi-Token-Vorhersage (MTP): Statt Wörter nacheinander vorherzusagen, prognostiziert dieser Ansatz mehrere Wörter gleichzeitig, indem Satzsegmente analysiert werden – was Genauigkeit und Geschwindigkeit steigert.Mixture of Experts (MoE): Dieses System nutzt mehrere neuronale Netze zur Datenverarbeitung, wodurch Effizienz und Leistung verbessert werden. DeepSeek V3 setzt 256 Netze ein, von denen acht pro Token-Verarbeitungsaufgabe aktiviert werden.Multi-Head-Latent-Attention (MLA): Diese Technik konzentriert sich auf entscheidende Satzelemente, extrahiert Schlüsseldetails wiederholt und minimiert so Fehleinschätzungen, während subtile Nuancen in den Daten erfasst werden.
Das chinesische Start-up DeepSeek behauptet, sein leistungsfähiges Modell DeepSeek V3 mit einem bescheidenen Budget von nur 6 Millionen US-Dollar und lediglich 2048 GPUs entwickelt zu haben.
 Bild: ensigame.com
Bild: ensigame.com
Analysten von SemiAnalysis deckten jedoch auf, dass DeepSeek über eine massive Infrastruktur verfügt, darunter rund 50.000 Nvidia-Hopper-GPUs, einschließlich 10.000 H800-, 10.000 hochmoderne H100-Modelle und zusätzliche H20-Einheiten. Diese Ressourcen, die auf mehrere Rechenzentren verteilt sind, unterstützen KI-Training, Forschung und Finanzmodellierung.
Die Serverinvestitionen des Unternehmens belaufen sich auf etwa 1,6 Milliarden US-Dollar, während die Betriebskosten bei fast 944 Millionen US-Dollar liegen.
DeepSeek, eine Tochtergesellschaft des chinesischen Hedgefonds High-Flyer, wurde 2023 ausgegliedert, um sich auf KI zu konzentrieren. Im Gegensatz zu den meisten Start-ups, die auf Cloud-Computing angewiesen sind, betreibt DeepSeek eigene Rechenzentren, was eine bessere Kontrolle über die Modelloptimierung und schnellere Innovation ermöglicht. Die eigenfinanzierte Struktur erhöht die Flexibilität und Entscheidungsfreiheit.
 Bild: ensigame.com
Bild: ensigame.com
DeepSeek lockt zudem Spitzentalente an – einige Forscher verdienen über 1,3 Millionen US-Dollar pro Jahr und stammen ausschließlich von renommierten chinesischen Universitäten.
Obwohl behauptet wird, dass DeepSeek V3 für gerade einmal 6 Millionen US-Dollar trainiert wurde, bezieht sich diese Zahl nur auf die GPU-Nutzung während des Pre-Trainings – Forschung, Feinabstimmung, Datenverarbeitung und Infrastrukturkosten sind nicht enthalten.
Seit seiner Gründung hat DeepSeek über 500 Millionen US-Dollar in die KI-Entwicklung gesteckt. Dank seiner schlanken Struktur kann das Unternehmen schneller und effektiver innovieren als größere, bürokratische Konkurrenten.
 Bild: ensigame.com
Bild: ensigame.com
DeepSeeks Aufstieg zeigt, dass ein unabhängiges, gut finanziertes KI-Unternehmen mit Branchenriesen mithalten kann. Experten betonen, dass sein Erfolg auf erheblichen Investitionen, technischen Fortschritten und einem hochqualifizierten Team beruht – auch wenn die Behauptung eines "kostengünstigen" KI-Modells etwas übertrieben ist.
Dennoch sind DeepSeeks Kosten deutlich niedriger als die der Konkurrenz. Zum Beispiel beliefen sich die Trainingskosten für DeepSeeks R1-Modell auf 5 Millionen US-Dollar, während ChatGPT4o mit 100 Millionen US-Dollar zu Buche schlug.

















