
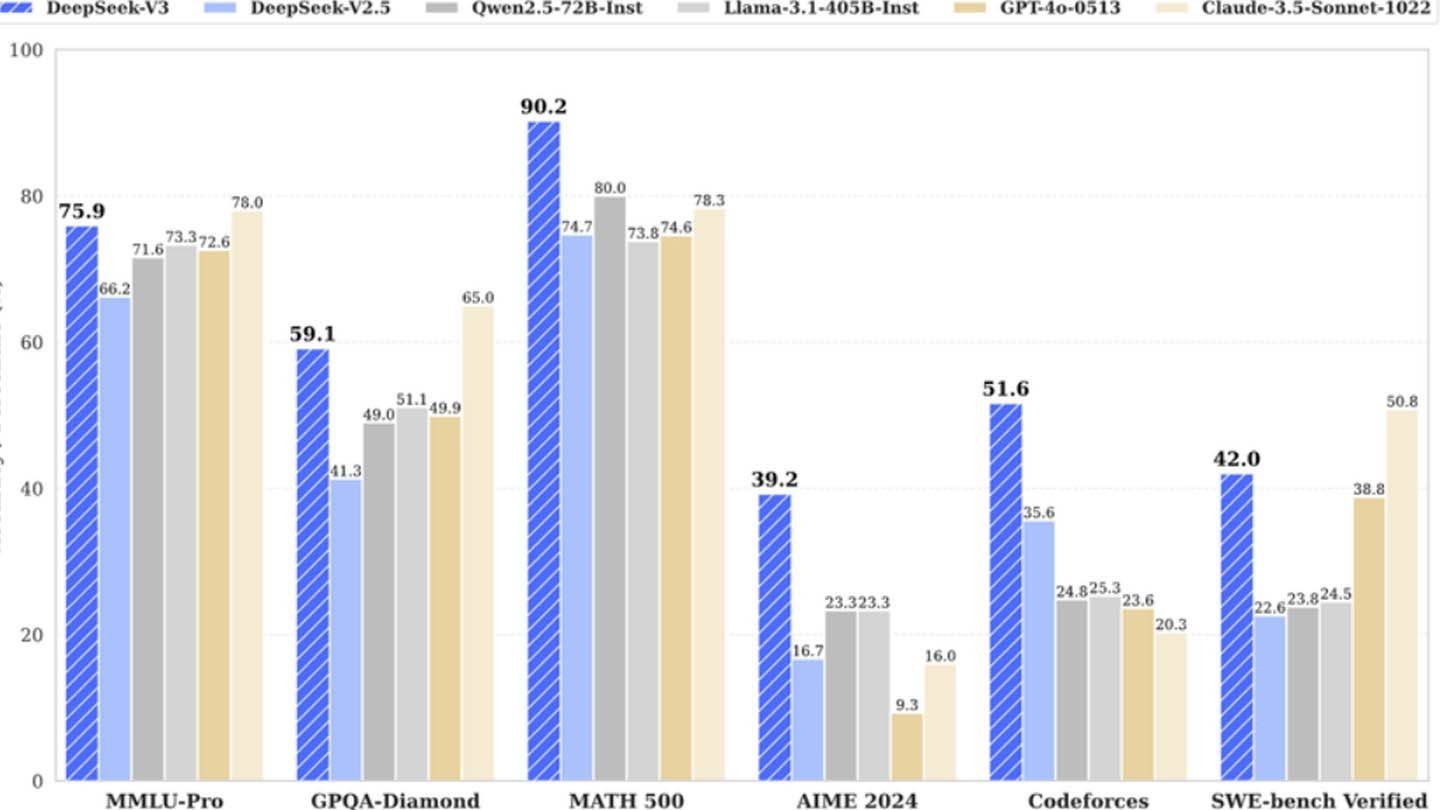
然而相比竞品,它依然更具成本优势
DeepSeek最新的聊天机器人用这句豪言开场:
我能以出人意料的洞见回答任何问题
这家公司的AI已成为行业重要参与者,甚至引发了英伟达股价的显著波动。
 图源:ensigame.com
图源:ensigame.com
其核心竞争力来自于独特的架构设计与训练方法:
多词元预测(MTP):通过分析语句片段同时预测多个词汇,而非逐词生成,显著提升准确率与速度
专家混合系统(MoE):调用多组神经网络协同处理数据,DeepSeek V3采用256组网络,每项任务激活其中8组
多头潜在注意力(MLA):聚焦语句关键要素,通过重复提炼核心信息以降低遗漏率
中国初创企业DeepSeek宣称,其重磅模型DeepSeek V3仅耗资600万美元,使用2048块GPU便完成开发。
 图源:ensigame.com
图源:ensigame.com
但SemiAnalysis分析师披露,DeepSeek实际部署了约5万块英伟达Hopper架构GPU,包括1万块H800、1万块高端H100以及多组H20加速器。这些设备分布于多个数据中心,支持AI训练、金融建模等业务。
其服务器总投资约16亿美元,年运营成本近9.44亿美元。
作为私募巨头幻方量化旗下AI子公司,DeepSeek于2023年独立运营。与依赖云计算的主流初创公司不同,DeepSeek自建数据中心使其能更高效地优化模型。这种重资产模式反而赋予其更强的技术迭代能力。
 图源:ensigame.com
图源:ensigame.com
团队招募清北等顶尖院校人才,部分研究员年薪超900万元人民币。
所谓"600万美元训练成本"仅涵盖预训练阶段的GPU开支,未包含算法研发、数据清洗等隐性投入。事实上,公司成立以来在AI领域的累计投入已超5亿美元。相较机构臃肿的巨头,其扁平结构更利于快速创新。
 图源:ensigame.com
图源:ensigame.com
DeepSeek的崛起证明,资金充沛的独立AI公司完全能挑战行业巨头。分析师指出,虽然"低成本AI"的宣传存在夸大,但相较竞品确实具备优势——其R1模型训练成本500万美元,仅为ChatGPT4o的1/20。

















