
しかし、競合他社よりもコスト効率が高い。
DeepSeekの最新AIチャットボットは、次の大胆な自己紹介で登場しました:
こんにちは、私はどんな質問にも洞察力ある回答を返すように作られています。その答えに驚くかもしれませんよ。
DeepSeekのAIは業界で有力なプレイヤーとして台頭し、NVIDIAの株価下落にも影響を与えました。
 画像: ensigame.com
画像: ensigame.com
このモデルの強みは、独自のアーキテクチャと先進的なトレーニング技術にあります:
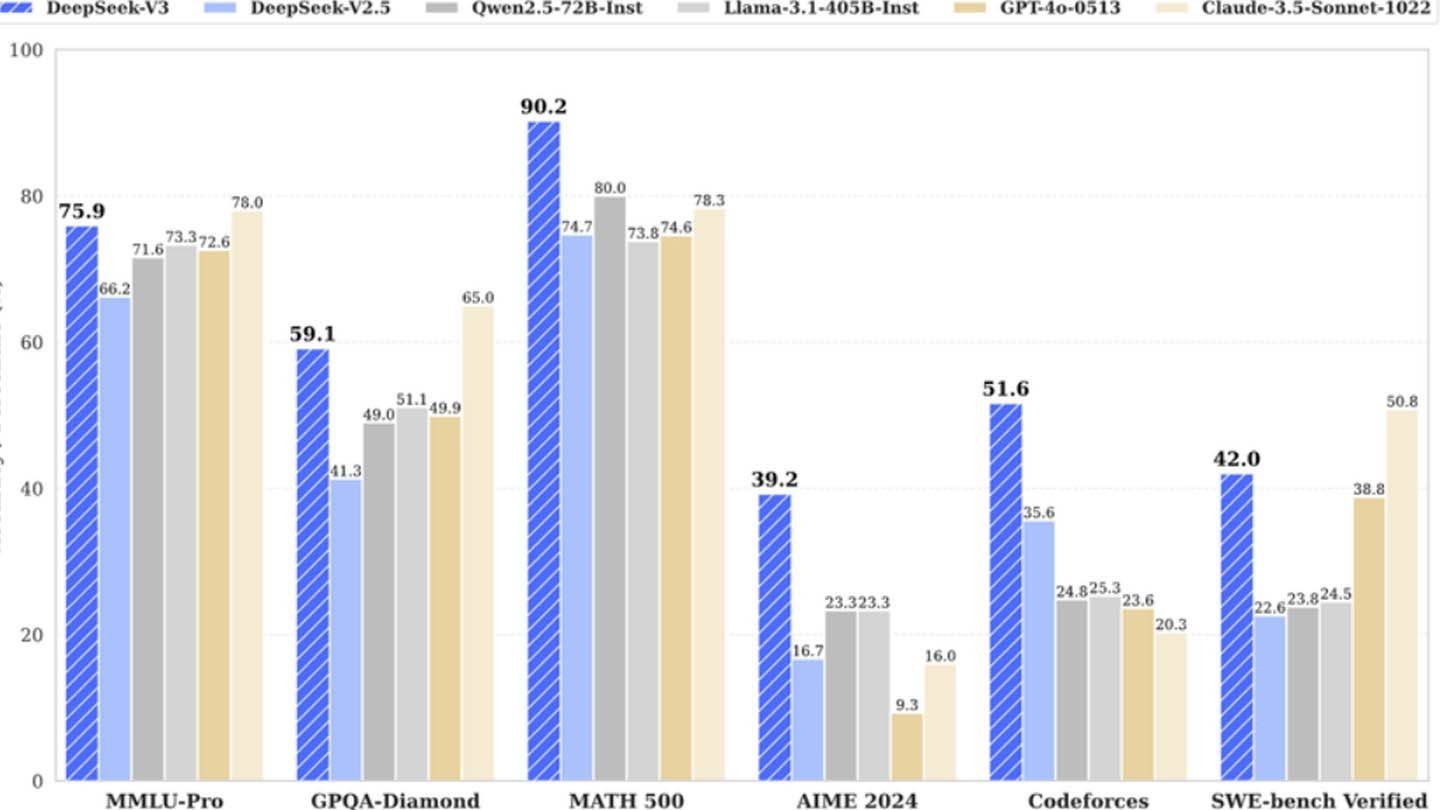
マルチトークン予測(MTP): 単語を1つずつ予測する代わりに、文のセグメントを分析して複数の単語を同時に予測。精度と速度の両方を向上させます。エキスパートの混合(MoE): 複数のニューラルネットワークを活用してデータを処理し、トレーニング効率とパフォーマンスを向上。DeepSeek V3は256のネットワークを備え、トークン処理タスクごとに8つを活性化させます。マルチヘッド・レイテント・アテンション(MLA): 文の重要な要素にフォーカスし、繰り返しキーディテールを抽出。見落としを最小限に抑えつつ、データ内の微妙なニュアンスも捉えます。
中国のスタートアップDeepSeekは、たった600万ドルの予算と2048基のGPUだけで、強力なDeepSeek V3モデルを開発したと主張しています。
 画像: ensigame.com
画像: ensigame.com
しかし、SemiAnalysisのアナリストによると、DeepSeekは約5万基のNvidia Hopper GPUという大規模なインフラを有しており、その内訳はH800が1万基、高度なH100が1万基、さらにH20ユニットも追加されています。これらのリソースは複数のデータセンターに分散され、AIトレーニング、研究、金融モデリングをサポートしています。
同社のサーバー投資総額は約16億ドル、運用コストは約9億4400万ドルに上ります。
中国のヘッジファンドHigh-Flyerの子会社であるDeepSeekは、2023年にAIに特化するため独立しました。クラウドコンピューティングに依存するほとんどのスタートアップとは異なり、DeepSeekは自社のデータセンターを所有し、モデル最適化の管理を強化し、迅速なイノベーションを実現しています。自己資金による構造は、柔軟性と意思決定の俊敏性を高めています。
 画像: ensigame.com
画像: ensigame.com
DeepSeekはまた、中国の名門大学出身のエリート研究者を集め、一部の研究者は年収130万ドル以上を得ています。
DeepSeek V3のトレーニングコストが600万ドルしかかからなかったという主張があるものの、この数字は事前トレーニング期間中のGPU使用量のみをカバーしており、研究、改良、データ処理、インフラコストは含まれていません。
創業以来、DeepSeekはAI開発に5億ドル以上を投資しています。そのリーンな組織構造は、大規模で官僚的な競合他社と比べて迅速かつ効果的なイノベーションを可能にします。
 画像: ensigame.com
画像: ensigame.com
DeepSeekの躍進は、十分な資金を持つ独立したAI企業が業界の巨人に匹敵しうることを示しています。専門家らはその成功要因として、多額の投資、技術的進歩、熟練したチームを挙げていますが、「低コスト」なAIモデルという主張は大げさだと指摘しています。
それでも、DeepSeekのコストは競合他社より明らかに低いです。例えば、DeepSeekのR1モデルのトレーニングコストは500万ドルだったのに対し、ChatGPT4oには1億ドルかかりました。

















